
Google aktualizuje limity rozmiaru crawlu plików. Dlaczego (prawdopodobnie) nie musisz panikować?
Znowu to samo. Google aktualizuje jedną linijkę w dokumentacji technicznej, a internetowi „guru SEO” już zacierają ręce, wieszcząc koniec świata i sprzedając audyty, które mają uratować Twoją stronę przed zagładą. Tym razem poszło o aktualizację limitów wielkości plików, które Googlebot może pobrać i zaindeksować. Brzmi groźnie? Może dla kogoś, kto prowadzi encyklopedię wielkości całego Internetu na jednej podstronie. Dla Ciebie – prawdopodobnie nie.
Zanim jednak zamkniesz ten artykuł, uznając, że temat Cię nie dotyczy – zatrzymaj się. Choć sama aktualizacja limitów jest w 99% przypadków techniczną ciekawostką, to stanowi doskonały pretekst, by zrozumieć, jak Googlebot „trawi” kod Twojej witryny i dlaczego „lekkość” kodu wciąż jest fundamentem skutecznego SEO.
Co dokładnie zmieniło Google w dokumentacji?
Zacznijmy od faktów, oddzielając je od marketingowego szumu. Google zaktualizowało swoją dokumentację dotyczącą limitów crawlowania (pobierania) plików. Nowe wytyczne precyzują:
- 2 MB – tyle wynosi limit dla plików HTML, które Googlebot pobierze i przetworzy w pierwszej kolejności.
- 64 MB – to limit dla plików PDF (co jest dobrą wiadomością dla serwisów z raportami i e-bookami).
- 15 MB – to ogólny, domyślny limit dla innych zasobów pobieranych przez roboty Google.
Co to oznacza w praktyce? Że Googlebot pobierze pierwsze 2 MB kodu HTML Twojej podstrony, a resztę… cóż, resztę może zignorować. Brzmi jak mało? Pozwól, że osadzę to w kontekście.
Dlaczego 2 MB to w świecie kodu HTML „nieskończoność”?
2 MB kodu HTML to mniej więcej tyle, co 400-stronicowa powieść upchnięta na jednej podstronie. Pamiętaj, mówimy tu o czystym kodzie tekstowym HTML, a nie o „wadze” całej strony widocznej dla użytkownika (która obejmuje zdjęcia, wideo, skrypty zewnętrzne). Przeciętna strona internetowa w 2025 roku ma kod HTML o wadze zaledwie ok. 22 KB (0,022 MB).
Aby przekroczyć limit 2 MB i narazić się na to, że Google „odetnie” część Twojej treści, Twoja strona musiałaby być 90 razy większa od rynkowej średniej. Jeśli Twój kod HTML waży 2 MB, to problemem nie jest indeksowanie Google, ale fakt, że Twoja strona prawdopodobnie wczytuje się tak wolno, że żaden użytkownik jej nie zobaczy.
Kogo ta zmiana rzeczywiście dotyczy?
- Gigantycznych serwisów e-commerce, które na jednej liście produktowej ładują tysiące wariantów.
- Źle napisanych aplikacji webowych (SPA), które „wypluwają” całą bazę danych bezpośrednio do kodu źródłowego.
- Stron z ekstremalnym długiem technicznym, gdzie kod jest zaśmiecony zbędnymi danymi.
Dla typowej strony firmowej, bloga, a nawet dużego sklepu internetowego – jesteś bezpieczny.
Techniczne SEO: Co naprawdę „tuczy” Twój kod?
Skoro wiemy już, że limit Google jest bezpiecznikiem dla ekstremalnych przypadków, warto zastanowić się, co w ogóle sprawia, że plik HTML rośnie. Zrozumienie tego pozwoli Ci utrzymać higienę kodu, co przekłada się na szybkość ładowania (Core Web Vitals) i łatwość indeksowania.
Googlebot nie „widzi” strony tak jak Ty. On widzi kod. Oto co najczęściej powoduje jego niepotrzebne puchnięcie (tzw. code bloat):
- Inline CSS i JavaScript: Zamiast trzymać style i skrypty w oddzielnych plikach (np. style.css), niektórzy deweloperzy lub wtyczki (page buildery) wrzucają je bezpośrednio do kodu HTML. To tysiące linijek tekstu, które Google musi pobrać, zanim dotrze do właściwej treści.
- Obrazy w formacie Base64: Czasami małe ikonki są zamieniane na ciąg znaków w kodzie HTML. Jeśli zrobisz to ze zdjęciem wysokiej jakości, Twój plik HTML może urosnąć o kilka megabajtów tekstu, który dla Googlebota jest bezużytecznym śmieciem na etapie analizy treści.
- Nadmiarowy kod DOM: Popularne kreatory stron (Elementor, Divi itp.) często generują tzw. „zupę divów” (div soup). Aby wyświetlić jeden prosty nagłówek, tworzą 10 zagnieżdżonych w sobie kontenerów. To wszystko to tekst, który waży.
- Skomentowany kod: Pozostawione przez programistów stare fragmenty kodu, które są niewidoczne dla użytkownika, ale widoczne dla robota i wliczają się do limitu wagowego.
Jak Googlebot rozumie kod i dlaczego „Fetch” to nie „Render”?
To najważniejsza sekcja dla zrozumienia technicznego SEO. Musisz rozróżnić dwa etapy pracy robota:
- Crawling (Fetch / Pobieranie): To tutaj obowiązuje limit (np. 15 MB lub 2 MB dla HTML). Googlebot łączy się z serwerem i prosi o plik. Jeśli plik jest za duży, połączenie zostaje przerwane po pobraniu limitu. Wszystko, co znajduje się w kodzie „niżej” (np. stopka, linki w dolnej części strony), może zostać niezauważone.
- Rendering (Renderowanie): Pobrany kod HTML jest następnie przetwarzany. Googlebot uruchamia JavaScript, buduje strukturę strony (DOM) i dopiero wtedy „widzi” to, co użytkownik.
Ważna uwaga: Limit dotyczy surowego przesyłu danych. Jeśli Twój serwer wysyła skompresowany plik (GZIP/Brotli), Googlebot pobiera go w tej formie. Dopiero po rozpakowaniu plik może być większy. Jednak limity w dokumentacji Google zazwyczaj odnoszą się do danych pobranych przez robota. Dlatego tak ważna jest kompresja po stronie serwera – pozwala ona „zmieścić” więcej treści w limicie przesyłu.
Jak sprawdzić, czy masz problem?
Nie musisz kupować drogiego audytu, aby sprawdzić, czy Twoja strona mieści się w limitach. Możesz to zrobić samodzielnie w 30 sekund.
- Metoda 1: „Zbadaj źródło”
Kliknij prawym przyciskiem myszy na swojej stronie i wybierz „Pokaż źródło strony” (View Page Source). Zapisz ten plik na dysku (CTRL+S / CMD+S) jako .html i sprawdź jego rozmiar we właściwościach pliku. Jeśli jest mniejszy niż 2 MB (a pewnie ma mniej niż 100 KB), śpij spokojnie. - Metoda 2: Chrome DevTools
- Otwórz swoją stronę.
- Naciśnij F12 (lub prawy przycisk -> Zbadaj).
- Przejdź do zakładki Network.
- Odśwież stronę (F5).
- Na samej górze listy znajdź pierwszy plik (zazwyczaj o nazwie Twojej domeny lub www).
- Spójrz na kolumnę „Size”. Interesuje Cię wartość przesłana (transfer) oraz wielkość zasobu (resource). Obie będą niemal na pewno w kilobajtach (kB).
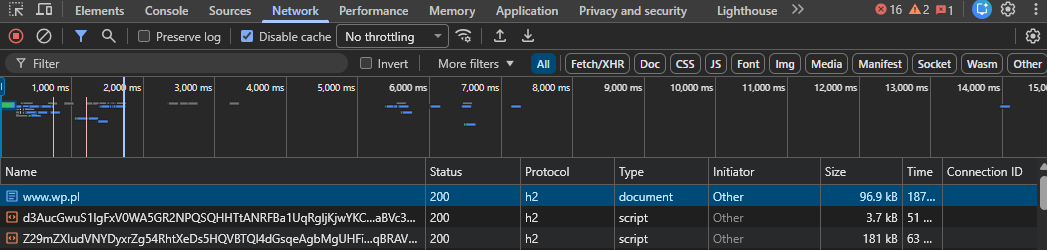
Przykład strony Wirtualna Polska – znana z tego, że między dziesiątkami reklam czasem pojawi się jakiś artykuł – strona waży poniżej 100KB czyli 1/20 limitu.
Nie daj się zwariować.
Aktualizacja dokumentacji Google to w tym przypadku ewolucja, a nie rewolucja. Wprowadzenie jasnego rozróżnienia (2 MB dla HTML, 15 MB ogólnie) pomaga deweloperom wielkich aplikacji, ale dla 99% właścicieli stron nic się nie zmienia.
Techniczne SEO jest ważne, ale polega ono na optymalizacji szybkości, struktury danych i dostępności treści, a nie na panicznym odchudzaniu pliku tekstowego, który i tak jest lekki jak piórko. Jeśli ktoś próbuje Cię nastraszyć, że „Twoja strona jest za duża dla Google”, poproś go o podanie konkretnej wagi pliku HTML. Zazwyczaj zapada wtedy cisza.
Co powinieneś zrobić teraz?
Sprawdź z ciekawości wagę swojej strony główniej (korzystając z metody powyżej). Jeśli jest w normie – gratulacje, masz jeden problem z głowy. Jeśli jednak zbliżasz się do 1-2 MB samej treści HTML, skonsultuj się z programistą – nie ze względu na Google, ale ze względu na Twoich użytkowników, którzy czekają wieki na załadowanie się strony.
Potrzebujesz rzetelnej analizy technicznej, a nie straszenia algorytmami?
Skontaktuj się z nami. Przeprowadzimy audyt, który skupi się na tym, co realnie wpływa na Twoją widoczność i sprzedaż oraz porozmawiajmy o Twoim SEO.
Źródło: https://developers.google.com/search/docs/crawling-indexing/googlebot#how-googlebot-accesses-your-site




